import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
from scipy.special import expit
from statsmodels.formula.api import ols
import causalpy as cp
%load_ext autoreload
%autoreload 2
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc_extras/model/marginal/graph_analysis.py:10: FutureWarning: `pytensor.graph.basic.io_toposort` was moved to `pytensor.graph.traversal.io_toposort`. Calling it from the old location will fail in a future release.
from pytensor.graph.basic import io_toposort
sample_kwargs = {
"draws": 1000,
"tune": 2000,
"chains": 4,
"cores": 4,
"target_accept": 0.95,
"progressbar": True,
"random_seed": 42,
"nuts_sampler": "numpyro",
}
Variable Selection Priors and Instrumental Variable Designs#
When building causal inference models, we face a fundamental dilemma: the bias-variance trade-off. We are tasked with finding the true causal effect of a treatment (\(T\)) on an outcome (\(Y\)) while controlling for every single confounder (\(X\))—variables that influence both \(T\) and \(Y\). Include too few variables, and we risk the catastrophic flaw of omitted variable bias (OVB), leading to inaccurate causal claims.Include too many irrelevant variables (noise), and we introduce noise that inflates our uncertainty, widens our posterior intervals, or, worse, creates multicollinearity that destabilizes our estimates.Traditional approaches force us to make hard, upfront decisions about which \(X\)’s to include. In ideal cases, this is driven by theory. But in the messy reality of data science, where we often have dozens of “potential” confounders, how do we make this choice?
We want to let the data help us make these decisions while still maintaining the principled probabilistic framework of Bayesian inference. This is where variable selection priors enter the scene. They allow us to encode our uncertainty about variable relevance directly into the prior, making variable selection part of the inference problem itself, not a separate, error-prone preprocessing step.
Let’s first simulate some data with some natural confounding structure and a known true treatment effect of 3.0. We enforce the idea of confounding on the treatment effect with a positive selection probability driving treatment and outcome. The challenge of modelling this data is to tease out the structure of the simultaneous equations in the system. For more details on this Bayesian structural causal modelling see here
def simulate_data(n=2500, alpha_true=3.0, rho=0.6, cate_estimation=False, n_zeros=50):
# Exclusion restrictions:
# X[0], X[1] affect both Y and T (confounders)
# X[2], X[3] affect ONLY T (instruments for T)
# X[4] affects ONLY Y (predictor of Y only)
betaY_core = np.array([0.5, -0.3, 0.0, 0.0, 0.4])
betaD_core = np.array([0.7, 0.1, -0.4, 0.3, 0.0])
betaY = np.concatenate([betaY_core, np.zeros(n_zeros)])
betaD = np.concatenate([betaD_core, np.zeros(n_zeros)])
p = len(betaY)
# noise variances and correlation
sigma_U = 1
sigma_V = 1
# design matrix (n × p) with mean-zero columns
X = np.random.normal(size=(n, p))
X = (X - X.mean(axis=0)) / X.std(axis=0)
mean = [0, 0]
cov = [[sigma_U**2, rho * sigma_U * sigma_V], [rho * sigma_U * sigma_V, sigma_V**2]]
errors = np.random.multivariate_normal(mean, cov, size=n)
U = errors[:, 0] # error in outcome equation
V = errors[:, 1] #
# continuous treatment
T_cont = X @ betaD + V
# latent variable for binary treatment
T_latent = X @ betaD + V
T_bin = np.random.binomial(n=1, p=expit(T_latent), size=n)
alpha_individual = 3.0 + 2.5 * X[:, 0]
# outcomes
Y_cont = alpha_true * T_cont + X @ betaY + U
if cate_estimation:
Y_bin = alpha_individual * T_bin + X @ betaY + U
else:
Y_bin = alpha_true * T_bin + X @ betaY + U
# combine into DataFrame
data = pd.DataFrame(
{
"Y_cont": Y_cont,
"Y_bin": Y_bin,
"T_cont": T_cont,
"T_bin": T_bin,
}
)
data["alpha"] = alpha_true + alpha_individual
for j in range(p):
data[f"feature_{j}"] = X[:, j]
data["Y_cont_scaled"] = (data["Y_cont"] - data["Y_cont"].mean()) / data[
"Y_cont"
].std(ddof=1)
data["Y_bin_scaled"] = (data["Y_bin"] - data["Y_bin"].mean()) / data["Y_bin"].std(
ddof=1
)
data["T_cont_scaled"] = (data["T_cont"] - data["T_cont"].mean()) / data[
"T_cont"
].std(ddof=1)
data["T_bin_scaled"] = (data["T_bin"] - data["T_bin"].mean()) / data["T_bin"].std(
ddof=1
)
return data
data = simulate_data(n_zeros=20)
instruments_data = data.copy()
features = [col for col in data.columns if "feature" in col]
formula = "Y_cont ~ T_cont + " + " + ".join(features)
instruments_formula = "T_cont ~ 1 + " + " + ".join(features)
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2500 entries, 0 to 2499
Data columns (total 34 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Y_cont 2500 non-null float64
1 Y_bin 2500 non-null float64
2 T_cont 2500 non-null float64
3 T_bin 2500 non-null int64
4 alpha 2500 non-null float64
5 feature_0 2500 non-null float64
6 feature_1 2500 non-null float64
7 feature_2 2500 non-null float64
8 feature_3 2500 non-null float64
9 feature_4 2500 non-null float64
10 feature_5 2500 non-null float64
11 feature_6 2500 non-null float64
12 feature_7 2500 non-null float64
13 feature_8 2500 non-null float64
14 feature_9 2500 non-null float64
15 feature_10 2500 non-null float64
16 feature_11 2500 non-null float64
17 feature_12 2500 non-null float64
18 feature_13 2500 non-null float64
19 feature_14 2500 non-null float64
20 feature_15 2500 non-null float64
21 feature_16 2500 non-null float64
22 feature_17 2500 non-null float64
23 feature_18 2500 non-null float64
24 feature_19 2500 non-null float64
25 feature_20 2500 non-null float64
26 feature_21 2500 non-null float64
27 feature_22 2500 non-null float64
28 feature_23 2500 non-null float64
29 feature_24 2500 non-null float64
30 Y_cont_scaled 2500 non-null float64
31 Y_bin_scaled 2500 non-null float64
32 T_cont_scaled 2500 non-null float64
33 T_bin_scaled 2500 non-null float64
dtypes: float64(33), int64(1)
memory usage: 664.2 KB
CausalPy’s Variable Selection module provides a way to encode our uncertainty about variable relevance directly into the prior distribution. Rather than choosing which predictors to include, we specify priors that allow coefficients to be shrunk toward zero (or exactly zero) when the data doesn’t support their inclusion. The key insight is that variable selection becomes part of the inference problem rather than a preprocessing step. The module offers two fundamentally different approaches to variable selection, each reflecting a different belief about how sparsity manifests in the world. For references to a discussion of variable selection priors we direct the reader to Kaplan [2024]
The Spike-and-Slab: Discrete Choices#
The inclusion probability is shared across coefficients and given a Beta prior:
This parameter represents the prior probability that a coefficient is non-zero. For example, \(\alpha_\pi = \beta_\pi = 2\) corresponds to a weakly informative prior centered at \(0.5\).
Relaxed Bernoulli approximation#
To enable efficient gradient-based sampling, the binary indicator \(\gamma_j\) is approximated using a continuous relaxation of the Bernoulli distribution. Specifically,
where \(T > 0\) is a temperature parameter. As \(T \to 0\), this approximation approaches a discrete Bernoulli distribution, while larger values of \(T\) yield smoother transitions.
This relaxed formulation allows the model to learn inclusion probabilities while remaining compatible with Hamiltonian Monte Carlo.
Interpretation#
Coefficients with posterior \(\gamma_j\) concentrated near zero are effectively excluded.
Coefficients with posterior \(\gamma_j\) concentrated near one are included.
Posterior means of \(\gamma_j\) can be interpreted as variable inclusion probabilities.
The spike-and-slab prior is most appropriate when the goal is explicit variable selection and when sparsity is expected.
The Regularised Horseshoe: Gentle Moderation#
The horseshoe prior takes a different philosophical stance. Instead of discrete selection, it says: effects exist on a continuum from negligible to substantial, and we should shrink them proportionally to their signal strength. Small effects get heavily shrunk (possibly to near-zero), while large effects escape shrinkage almost entirely.
Horseshoe Prior#
The horseshoe prior is a continuous shrinkage prior designed for sparse or near-sparse signals. Unlike spike-and-slab, it does not explicitly set coefficients to zero, but instead shrinks most coefficients strongly toward zero while allowing a small number of large signals to escape shrinkage.
Each coefficient is modeled as
Global shrinkage#
The global shrinkage parameter \(\tau\) controls the overall level of shrinkage applied to all coefficients:
Smaller values of \(\tau\) result in stronger overall shrinkage. When not specified manually, \(\tau_0\) may be set using a data-adaptive rule of thumb based on the expected number of nonzero coefficients and the sample size.
Local shrinkage#
Each coefficient has an associated local shrinkage parameter:
These local parameters allow individual coefficients to escape global shrinkage when strongly supported by the data.
Regularization#
To improve numerical stability and avoid excessively large coefficients, the local shrinkage parameters are regularized following the regularized horseshoe formulation:
where
This regularization limits the influence of extremely large local shrinkage parameters while preserving the heavy-tailed behavior of the horseshoe prior.
Interpretation#
Most coefficients are shrunk aggressively toward zero.
A small number of coefficients may remain large if supported by the data.
There is no explicit inclusion indicator; shrinkage is continuous.
The effective shrinkage applied to coefficient \(j\) is \(\tau \cdot \tilde{\lambda}_j\).
The horseshoe prior is well suited for predictive modeling and regularization when strict variable inclusion decisions are not required.
Choosing Between Spike-and-Slab and Horseshoe#
Use spike-and-slab when:
Explicit variable selection is required
Inclusion probabilities are of substantive interest
Strong sparsity is expected
Use horseshoe when:
Many predictors may have small but nonzero effects
Prediction is the primary goal
Continuous shrinkage is preferred over hard selection
Both priors can substantially improve inference in high-dimensional or weakly identified models compared to standard Normal priors.
Spike and Slab: Hyperparameters for Variable Selection Priors#
You can control the behaviour of the variable selection priors through some of the hyperparameters available. For the spike and slab prior, the most important hyperparamers are temperature, pi_alpha, and pi_beta.
Because our sampler doesn’t like discrete variables, we’re approximating a bernoulli outcome in our sampling to define the spike and slab. The approximation is governed by the temperature parameter. The default value of 0.1 works well in most cases, creating indicators that cluster near 0 or 1 without causing sampling difficulties.
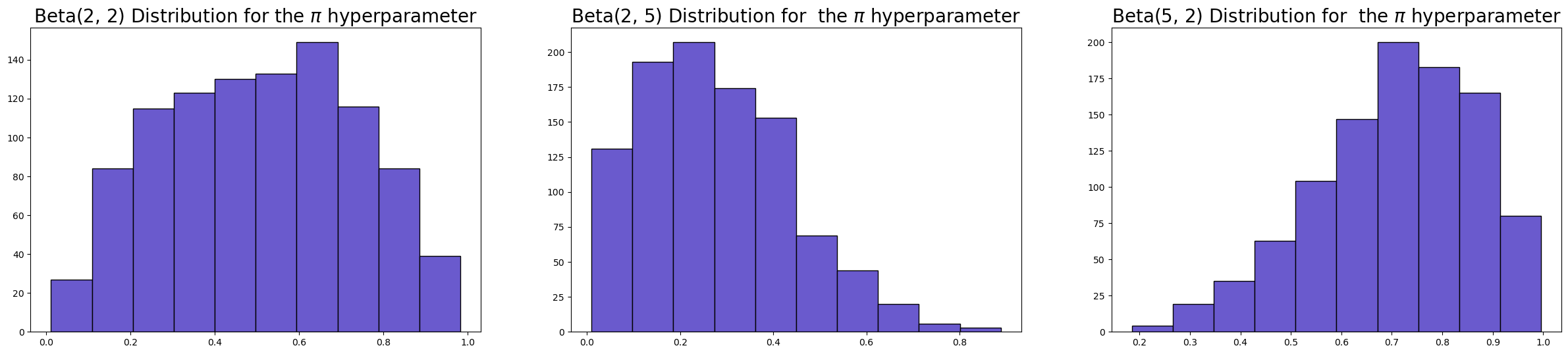
The selection probability parameters pi_alpha and pi_beta encode your prior belief about sparsity. With both set to 2 (the default), you’re placing a Beta(2,2) prior on π, the overall proportion of selected variables. This is symmetric around 0.5 but slightly concentrated there—you’re saying “I don’t know how many variables are relevant, but probably not all of them and probably not none of them.” These hyper-parameters inform the generation of \(\gamma\) which is pulled toward zero or one depending on the hyperparameters.
Show code cell source
fig, axs = plt.subplots(1, 3, figsize=(30, 6))
axs = axs.flatten()
axs[0].hist(pm.draw(pm.Beta.dist(2, 2), 1000), ec="black", color="slateblue")
axs[0].set_title(r"Beta(2, 2) Distribution for the $\pi$ hyperparameter", size=20)
axs[1].hist(pm.draw(pm.Beta.dist(2, 5), 1000), ec="black", color="slateblue")
axs[1].set_title(r"Beta(2, 5) Distribution for the $\pi$ hyperparameter", size=20)
axs[2].hist(pm.draw(pm.Beta.dist(5, 2), 1000), ec="black", color="slateblue")
axs[2].set_title(r"Beta(5, 2) Distribution for the $\pi$ hyperparameter", size=20);
We’ll now fit two models and estimate the implied treatment effect. We compare two models, the first with a normal(0, 1) prior on the \(\beta\) coefficients and then the same model that uses spike and slab priors on the input variables.
# =========================================================================
# Model 1: Normal priors (no selection)
# =========================================================================
print("\n" + "-" * 80)
print("Model 1: Normal Priors (No Variable Selection)")
print("-" * 80)
result_normal = cp.InstrumentalVariable(
instruments_data=instruments_data,
data=data,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type=None, # No variable selection
priors={
"mus": [0, 0],
"sigmas": [1, 1],
"eta": 1,
"lkj_sd": 1,
},
)
# =========================================================================
# Model 2: Spike-and-Slab priors
# =========================================================================
print("\n" + "-" * 80)
print("Model 2: Spike-and-Slab Priors")
print("-" * 80)
result_spike_slab = cp.InstrumentalVariable(
instruments_data=instruments_data,
data=data,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type="spike_and_slab",
vs_hyperparams={
"pi_alpha": 2,
"pi_beta": 2,
"slab_sigma": 2,
"temperature": 0.1,
"outcome": True,
}, # Include outcome variable selection
)
Show code cell output
--------------------------------------------------------------------------------
Model 1: Normal Priors (No Variable Selection)
--------------------------------------------------------------------------------
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/experiments/instrumental_variable.py:137: UserWarning: Warning. The treatment variable is not Binary.
We will use the multivariate normal likelihood
for continuous treatment.
self.input_validation()
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 150/3000 [00:03<00:45, 62.32it/s]
Running chain 0: 10%|█ | 300/3000 [00:06<00:47, 56.87it/s]
Running chain 0: 15%|█▌ | 450/3000 [00:09<00:51, 49.24it/s]
Running chain 0: 20%|██ | 600/3000 [00:14<00:59, 40.16it/s]
Running chain 0: 25%|██▌ | 750/3000 [00:18<00:54, 41.24it/s]
Running chain 0: 30%|███ | 900/3000 [00:22<00:53, 39.30it/s]
Running chain 0: 35%|███▌ | 1050/3000 [00:26<00:49, 39.52it/s]
Running chain 0: 40%|████ | 1200/3000 [00:31<00:50, 35.69it/s]
Running chain 0: 45%|████▌ | 1350/3000 [00:34<00:44, 36.90it/s]
Running chain 0: 50%|█████ | 1500/3000 [00:38<00:39, 38.09it/s]
Running chain 0: 55%|█████▌ | 1650/3000 [00:42<00:35, 37.66it/s]
Running chain 0: 60%|██████ | 1800/3000 [00:46<00:32, 37.46it/s]
Running chain 0: 65%|██████▌ | 1950/3000 [00:50<00:26, 39.18it/s]
Running chain 0: 70%|███████ | 2100/3000 [00:54<00:24, 37.11it/s]
Running chain 0: 75%|███████▌ | 2250/3000 [00:59<00:21, 34.79it/s]
Running chain 0: 80%|████████ | 2400/3000 [01:04<00:17, 33.35it/s]
Running chain 0: 85%|████████▌ | 2550/3000 [01:09<00:14, 31.86it/s]
Running chain 0: 90%|█████████ | 2700/3000 [01:14<00:09, 31.06it/s]
Running chain 0: 95%|█████████▌| 2850/3000 [01:19<00:04, 30.40it/s]
Running chain 2: 100%|██████████| 3000/3000 [01:20<00:00, 37.29it/s]
Running chain 1: 100%|██████████| 3000/3000 [01:22<00:00, 36.51it/s]
Running chain 3: 100%|██████████| 3000/3000 [01:23<00:00, 35.77it/s]
Running chain 0: 100%|██████████| 3000/3000 [01:24<00:00, 35.34it/s]
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/experiments/instrumental_variable.py:137: UserWarning: Warning. The treatment variable is not Binary.
We will use the multivariate normal likelihood
for continuous treatment.
self.input_validation()
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/pymc_models.py:900: UserWarning: Variable selection priors specified. The 'mus' and 'sigmas' in the priors dict will be ignored for beta coefficients in the treatment equation.Only 'eta' and 'lkj_sd' will be used from the priors dictwhere applicable.
self.build_model(
--------------------------------------------------------------------------------
Model 2: Spike-and-Slab Priors
--------------------------------------------------------------------------------
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 150/3000 [00:10<02:56, 16.11it/s]
Running chain 0: 10%|█ | 300/3000 [00:22<03:11, 14.13it/s]
Running chain 0: 15%|█▌ | 450/3000 [00:34<03:08, 13.51it/s]
Running chain 0: 20%|██ | 600/3000 [00:45<03:01, 13.20it/s]
Running chain 0: 25%|██▌ | 750/3000 [00:58<02:54, 12.87it/s]
Running chain 0: 30%|███ | 900/3000 [01:09<02:43, 12.85it/s]
Running chain 0: 35%|███▌ | 1050/3000 [01:21<02:31, 12.89it/s]
Running chain 0: 35%|███▌ | 1050/3000 [01:31<02:31, 12.89it/s]
Running chain 0: 40%|████ | 1200/3000 [01:32<02:19, 12.93it/s]
Running chain 0: 45%|████▌ | 1350/3000 [01:44<02:07, 12.95it/s]
Running chain 0: 50%|█████ | 1500/3000 [01:55<01:55, 12.96it/s]
Running chain 0: 55%|█████▌ | 1650/3000 [02:08<01:46, 12.72it/s]
Running chain 0: 60%|██████ | 1800/3000 [02:20<01:34, 12.66it/s]
Running chain 0: 60%|██████ | 1800/3000 [02:31<01:34, 12.66it/s]
Running chain 0: 65%|██████▌ | 1950/3000 [02:32<01:23, 12.59it/s]
Running chain 0: 70%|███████ | 2100/3000 [02:43<01:10, 12.68it/s]
Running chain 0: 75%|███████▌ | 2250/3000 [02:55<00:59, 12.70it/s]
Running chain 0: 80%|████████ | 2400/3000 [03:07<00:47, 12.60it/s]
Running chain 0: 85%|████████▌ | 2550/3000 [03:19<00:35, 12.66it/s]
Running chain 0: 90%|█████████ | 2700/3000 [03:31<00:23, 12.71it/s]
Running chain 0: 95%|█████████▌| 2850/3000 [03:42<00:11, 12.93it/s]
Running chain 2: 100%|██████████| 3000/3000 [03:52<00:00, 12.91it/s]
Running chain 0: 100%|██████████| 3000/3000 [03:53<00:00, 12.83it/s]
Running chain 1: 100%|██████████| 3000/3000 [03:55<00:00, 12.75it/s]
Running chain 3: 100%|██████████| 3000/3000 [03:55<00:00, 12.74it/s]
There were 39 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
The models have quite a distinct structure. Compare the normal IV model with non variable selection priors.
pm.model_to_graphviz(result_normal.model)

Now compare the structure of the spike and slab model. As before we’re fitting a joint model of treatment and outcome. But now we specify hierarchical priors over the beta coefficients to “select” the variables of real importance. In the IV case this is particularly interesting because it helps mitigate the risk of over-parameterisation with weak instruments. In effect the sparsity priors act like a “instrument discovery” mechanism when used in this joint modelling context.
pm.model_to_graphviz(result_spike_slab.model)

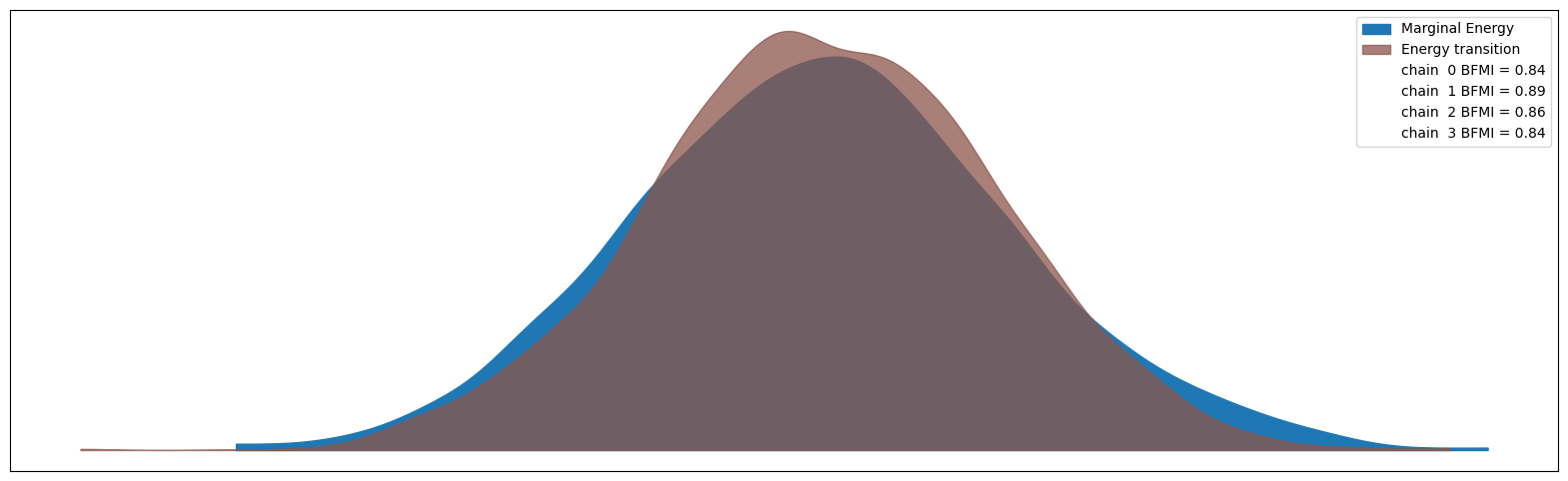
Despite seeing some divergences in our spike and slab model, most other sampler health metrics seem healthy. The rhat values are all close to 1.0 and the effective sample sizes are reasonable. The divergences may be a sign that the temperature parameter could be adjusted, but overall the model seems to have converged adequately for our purposes here. This is also reflected in the energy plot below - the higher overlap in the energy distributions the better.
az.plot_energy(result_spike_slab.idata, figsize=(20, 6));
And since we know the true data generating conditions we can also assess the derived posterior treatment estimates. This also lets us see a likely cause of the divergences, the model is torn between a slightly bi-modal distribution in the focal parameters as it oscillates between two plausible solutions for the treatment effect.
fig, axs = plt.subplots(1, 2, figsize=(20, 6))
axs = axs.flatten()
az.plot_posterior(
result_normal.idata,
var_names=["beta_z"],
coords={"covariates": ["T_cont"]},
ax=axs[0],
label="Normal",
point_estimate="median",
)
az.plot_posterior(
result_spike_slab.idata,
var_names=["beta_z"],
coords={"covariates": ["T_cont"]},
ax=axs[1],
color="green",
label="spike and slab",
point_estimate="median",
)
axs[0].axvline(3, color="black", linestyle="--", label="True value")
axs[1].axvline(3, color="black", linestyle="--", label="True value");
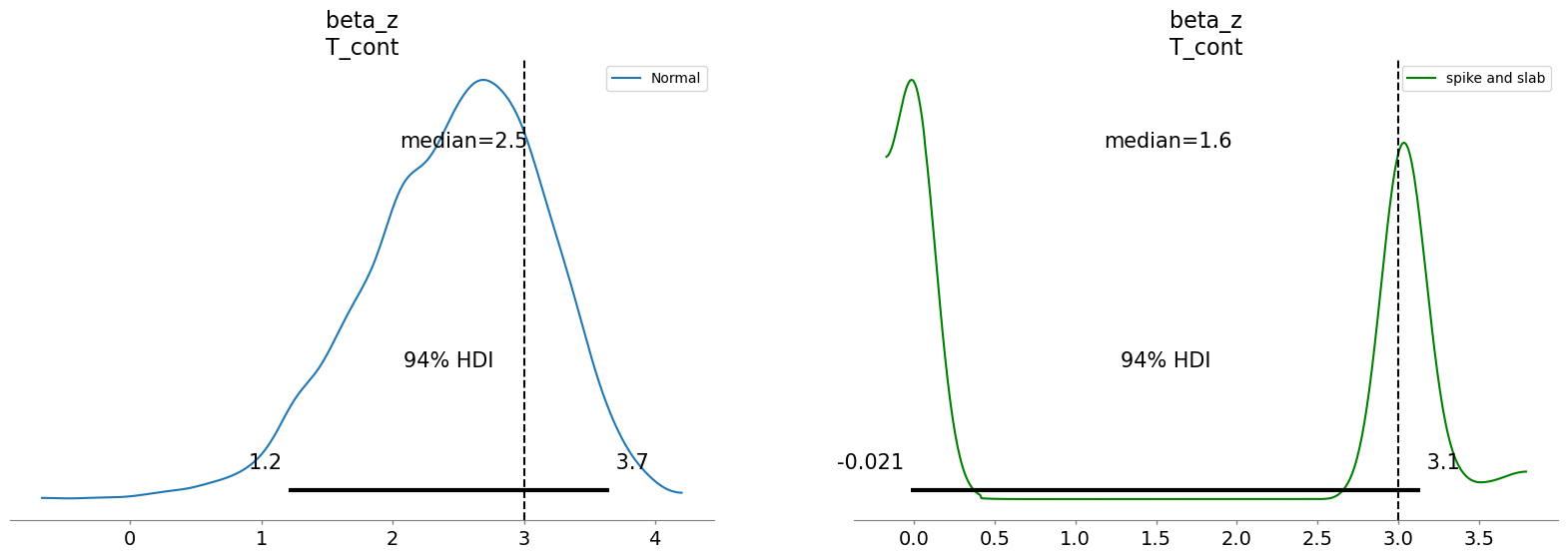
This plot suggests that the spike and slab prior was split between 0’ing out our treatment and allocating it a mass around the true value. This will not always work but it is a sensible practice to at least sensitivity check difference between the estimates under different prior settings. We can observe how aggressively the spike and slab prior worked to cull or removal unwanted variables from each model by comparing the values on the coefficients across each model. We might want to adjust the level of aggression in the temperature hyperparameter.
axs = az.plot_forest(
[result_spike_slab.idata, result_normal.idata],
var_names=["beta_z"],
combined=True,
model_names=["Spike and Slab", "Normal"],
r_hat=True,
)
axs[0].set_title("Parameter Comparison Outcome Model \n Baseline v Spike and Slab");
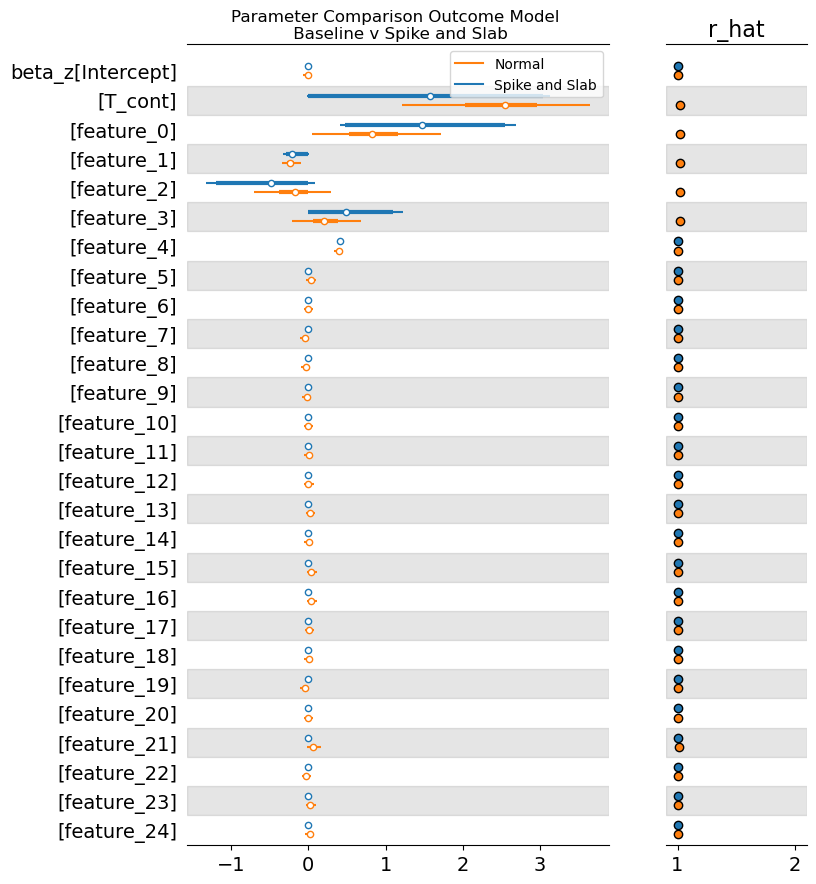
The parameter estimates are healthy for both models. With the spike and slab being a little bit more aggressive. But differences are more pronounced in the regularisation of the instruments.
The Treatment Model#
Variable selection is applied to both the outcome and the treatment model. In this way we calibrate our parameters to the joint patterns of realisations between these two endogenous variables. The Normal model (with all covariates included) is the baseline, showing the impact of including many irrelevant variables. Its posterior is centered correctly but is generally wider, reflecting the increased uncertainty/variance due to the noise covariates.
The Spike-and-Slab prior performs better here. This suggests it was successful in decisively excluding the noise variables, reducing the model’s overall variance.
axs = az.plot_forest(
[result_spike_slab.idata, result_normal.idata],
var_names=["beta_t"],
combined=True,
model_names=["Spike and Slab", "Normal"],
r_hat=True,
)
axs[0].set_title("Parameter Comparison Treatment Model \n Baseline v Spike and Slab");

The spike and slab prior can also output direct inclusion probabilities that can be used for communication regarding which variables were “selected” in the process.
summary = result_spike_slab.model.vs_prior_outcome.get_inclusion_probabilities(
result_spike_slab.idata, "beta_z"
)
summary
| prob | selected | gamma_mean | |
|---|---|---|---|
| 0 | 0.00275 | False | 0.003681 |
| 1 | 0.50450 | True | 0.497437 |
| 2 | 0.82400 | True | 0.821592 |
| 3 | 0.28050 | False | 0.309178 |
| 4 | 0.51900 | True | 0.498212 |
| 5 | 0.49600 | False | 0.488703 |
| 6 | 0.74550 | True | 0.762753 |
| 7 | 0.00075 | False | 0.001799 |
| 8 | 0.00500 | False | 0.007980 |
| 9 | 0.01675 | False | 0.020229 |
| 10 | 0.00425 | False | 0.005286 |
| 11 | 0.00450 | False | 0.005309 |
| 12 | 0.00200 | False | 0.002491 |
| 13 | 0.00325 | False | 0.003996 |
| 14 | 0.00500 | False | 0.005822 |
| 15 | 0.00200 | False | 0.002483 |
| 16 | 0.00525 | False | 0.005774 |
| 17 | 0.00025 | False | 0.001633 |
| 18 | 0.00275 | False | 0.003535 |
| 19 | 0.00200 | False | 0.002936 |
| 20 | 0.00275 | False | 0.003078 |
| 21 | 0.00350 | False | 0.004699 |
| 22 | 0.00300 | False | 0.003769 |
| 23 | 0.00300 | False | 0.003803 |
| 24 | 0.00425 | False | 0.006697 |
| 25 | 0.00075 | False | 0.001795 |
| 26 | 0.00525 | False | 0.006807 |
Horseshoe#
The horsehoe prior takes a continuous philosophical stance. Instead of discrete selection, it says: effects exist on a spectrum from negligible to substantial, and we should shrink them proportionally to their signal strength.
It uses a hierarchical structure where the coefficient \(\beta_j\) is determined by a global shrinkage parameter (\(\tau\)) and a local shrinkage parameter so that effects get pulled strongly toward zero (but rarely exactly zero) but there is a chance for counterfailing effects on each individual variable. Large effects escape shrinkage almost entirely, as if they are too big for the horseshoe’s magnetic pull.This method embraces probabilistic humility. It’s less decisive than the spike-and-slab, but it mitigates the risk of completely zeroing out the small, but real, contributions of certain variables — a risk that the spike-and-slab takes.
The key to the implementation is the hierarchical \(\lambda\) component:
is composed of individual local shrinkage parameters and \(c^2\) is a regularization parameter that prevents over-shrinkage of genuinely large signals.
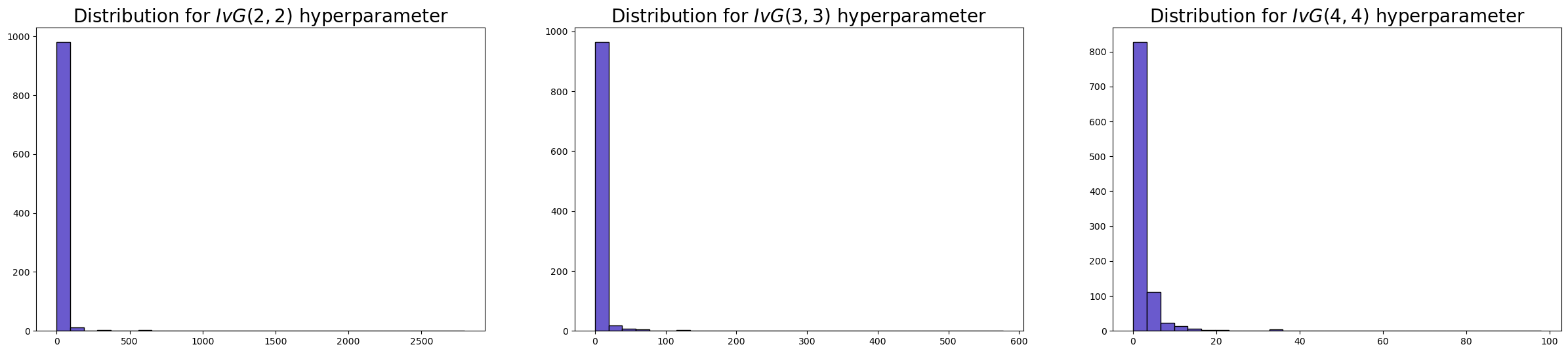
The \(\tau_0\) hyperparameter#
Like the temperature parameter in the spike and slab model, the \(\tau_{0}\) parameter determines the overall level of sparsity expected in the model. However, the \(\tau_{0}\) will by default be derived from the data and the number of covariates in your data. While both the horseshoe and spike-and-slab priors address variable selection and sparsity, they embody fundamentally different philosophies about how to achieve these goals. The horseshoe embraces continuity, creating a smooth gradient of shrinkage where all coefficients remain in the model but are pulled toward zero with varying intensity.
Show code cell source
fig, axs = plt.subplots(1, 3, figsize=(30, 6))
axs = axs.flatten()
axs[0].hist(
pm.draw(pm.InverseGamma.dist(2, 2), 1000) ** 2,
ec="black",
color="slateblue",
bins=30,
)
axs[0].set_title(r"Distribution for $IvG(2, 2)$ hyperparameter", size=20)
axs[1].hist(
pm.draw(pm.InverseGamma.dist(3, 3), 1000) ** 2,
ec="black",
color="slateblue",
bins=30,
)
axs[1].set_title(r"Distribution for $IvG(3, 3)$ hyperparameter", size=20)
axs[2].hist(
pm.draw(pm.InverseGamma.dist(4, 4), 1000) ** 2,
ec="black",
color="slateblue",
bins=30,
)
axs[2].set_title(r"Distribution for $IvG(4, 4)$ hyperparameter", size=20);
# =========================================================================
# Model 2: Horseshoe priors
# =========================================================================
print("\n" + "-" * 80)
print("Model 3: Horseshoe Priors")
print("-" * 80)
result_horseshoe = cp.InstrumentalVariable(
instruments_data=instruments_data,
data=data,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type="horseshoe",
vs_hyperparams={"c2_alpha": 3, "c2_beta": 3, "outcome": True},
)
Show code cell output
--------------------------------------------------------------------------------
Model 3: Horseshoe Priors
--------------------------------------------------------------------------------
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/experiments/instrumental_variable.py:137: UserWarning: Warning. The treatment variable is not Binary.
We will use the multivariate normal likelihood
for continuous treatment.
self.input_validation()
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/pymc_models.py:900: UserWarning: Variable selection priors specified. The 'mus' and 'sigmas' in the priors dict will be ignored for beta coefficients in the treatment equation.Only 'eta' and 'lkj_sd' will be used from the priors dictwhere applicable.
self.build_model(
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 150/3000 [00:13<03:33, 13.33it/s]
Running chain 0: 10%|█ | 300/3000 [00:25<03:32, 12.73it/s]
Running chain 0: 15%|█▌ | 450/3000 [00:36<03:15, 13.07it/s]
Running chain 0: 20%|██ | 600/3000 [00:48<03:06, 12.84it/s]
Running chain 0: 20%|██ | 600/3000 [00:59<03:06, 12.84it/s]
Running chain 0: 25%|██▌ | 750/3000 [01:00<02:56, 12.73it/s]
Running chain 0: 30%|███ | 900/3000 [01:11<02:41, 13.02it/s]
Running chain 0: 35%|███▌ | 1050/3000 [01:21<02:21, 13.74it/s]
Running chain 0: 40%|████ | 1200/3000 [01:30<02:04, 14.46it/s]
Running chain 0: 45%|████▌ | 1350/3000 [01:39<01:50, 14.96it/s]
Running chain 0: 50%|█████ | 1500/3000 [01:48<01:36, 15.59it/s]
Running chain 0: 55%|█████▌ | 1650/3000 [01:58<01:29, 15.13it/s]
Running chain 0: 60%|██████ | 1800/3000 [02:10<01:22, 14.52it/s]
Running chain 0: 65%|██████▌ | 1950/3000 [02:18<01:08, 15.42it/s]
Running chain 0: 70%|███████ | 2100/3000 [02:29<01:00, 14.82it/s]
Running chain 0: 75%|███████▌ | 2250/3000 [02:41<00:53, 14.07it/s]
Running chain 2: 100%|██████████| 3000/3000 [02:48<00:00, 17.82it/s]
Running chain 0: 80%|████████ | 2400/3000 [02:53<00:44, 13.61it/s]
Running chain 0: 85%|████████▌ | 2550/3000 [03:05<00:33, 13.34it/s]
Running chain 0: 90%|█████████ | 2700/3000 [03:16<00:22, 13.24it/s]
Running chain 1: 100%|██████████| 3000/3000 [03:23<00:00, 14.78it/s]
Running chain 0: 95%|█████████▌| 2850/3000 [03:28<00:11, 13.13it/s]
Running chain 0: 100%|██████████| 3000/3000 [03:39<00:00, 13.64it/s]
Running chain 3: 100%|██████████| 3000/3000 [03:58<00:00, 12.56it/s]
There were 11 divergences after tuning. Increase `target_accept` or reparameterize.
Similar to the inclusion probabilities in the spike and slab model, a horseshoe model can output the relative shrinkage factor that gets applied to each variables inclusion. This method of variable is less decisive than spike and slab, but also mitigates case of completely zero-ing the small but real contributions of certain variables.
summary = result_horseshoe.model.vs_prior_outcome.get_shrinkage_factors(
result_horseshoe.idata, "beta_z"
)
summary
| shrinkage_factor | lambda_tilde | tau | |
|---|---|---|---|
| 0 | 0.017171 | 1.230544 | 0.008792 |
| 1 | 2.898983 | 207.753649 | 0.008792 |
| 2 | 1.029165 | 73.754440 | 0.008792 |
| 3 | 0.684408 | 49.047602 | 0.008792 |
| 4 | 0.053761 | 3.852716 | 0.008792 |
| 5 | 0.033660 | 2.412195 | 0.008792 |
| 6 | 0.945174 | 67.735216 | 0.008792 |
| 7 | 0.020109 | 1.441065 | 0.008792 |
| 8 | 0.028422 | 2.036869 | 0.008792 |
| 9 | 0.037798 | 2.708790 | 0.008792 |
| 10 | 0.019566 | 1.402159 | 0.008792 |
| 11 | 0.017802 | 1.275745 | 0.008792 |
| 12 | 0.017163 | 1.229967 | 0.008792 |
| 13 | 0.017461 | 1.251349 | 0.008792 |
| 14 | 0.018941 | 1.357386 | 0.008792 |
| 15 | 0.019241 | 1.378894 | 0.008792 |
| 16 | 0.018774 | 1.345398 | 0.008792 |
| 17 | 0.021245 | 1.522514 | 0.008792 |
| 18 | 0.019549 | 1.400997 | 0.008792 |
| 19 | 0.018454 | 1.322467 | 0.008792 |
| 20 | 0.018959 | 1.358682 | 0.008792 |
| 21 | 0.022002 | 1.576741 | 0.008792 |
| 22 | 0.018171 | 1.302246 | 0.008792 |
| 23 | 0.024186 | 1.733299 | 0.008792 |
| 24 | 0.024056 | 1.723988 | 0.008792 |
| 25 | 0.017552 | 1.257868 | 0.008792 |
| 26 | 0.023149 | 1.658983 | 0.008792 |
fig, axs = plt.subplots(1, 2, figsize=(20, 6))
axs = axs.flatten()
az.plot_posterior(
result_normal.idata,
var_names=["beta_z"],
coords={"covariates": ["T_cont"]},
ax=axs[0],
point_estimate="median",
)
az.plot_posterior(
result_horseshoe.idata,
var_names=["beta_z"],
coords={"covariates": ["T_cont"]},
ax=axs[1],
color="green",
point_estimate="median",
)
axs[0].axvline(3, color="black", linestyle="--")
axs[1].axvline(3, color="black", linestyle="--");
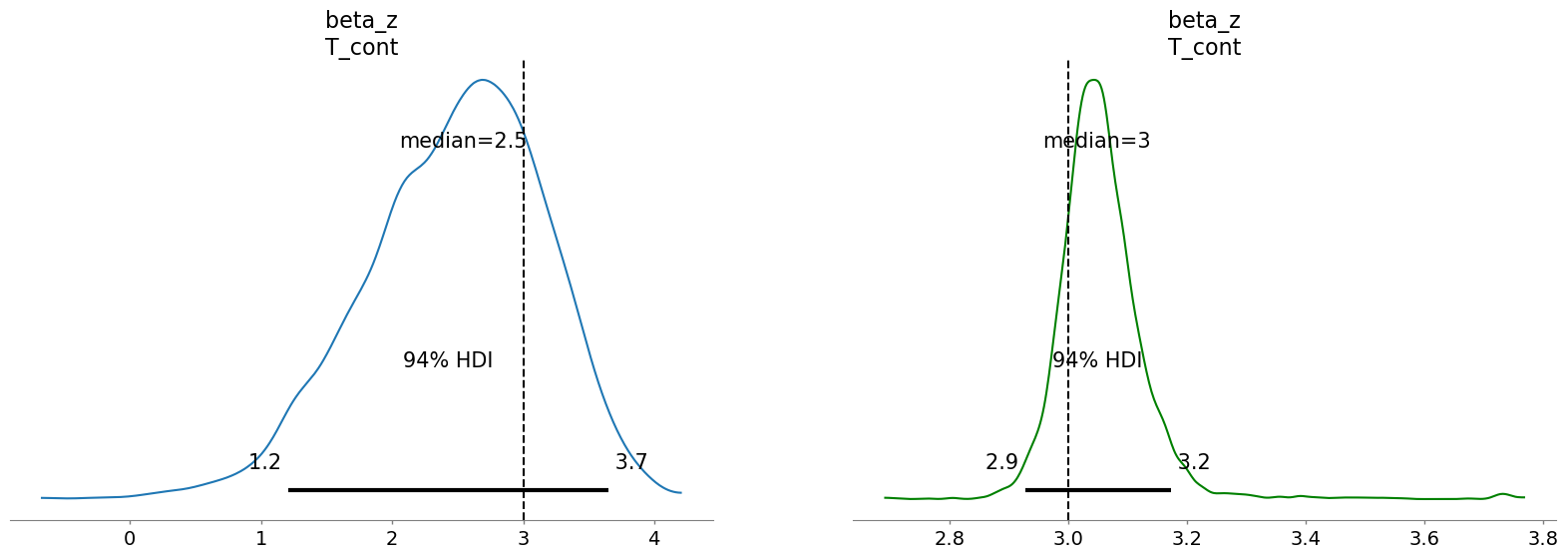
In this case it seems the horseshoe prior is also able to recover the true value of the treatment effect, and does so more confidently than in the simpler IV with normal(0, 1) regularisation.
Binary Treatment Case#
Our data generating function output two different simulation scenarios, where the treatment was either continuous or binary. This allows us to demonstrate the joint modelling of the binary treatment outcome which uses a Bernoulli likelihood for the treatment variable and latent confounding to model the joint realisation of treatment and outcome.
This model estimates causal effects in settings with a binary, potentially endogenous treatment and a continuous outcome using a Bayesian control-function approach. It is designed for applications where standard linear instrumental variables methods are inappropriate due to the discrete nature of the treatment, but where full joint latent-variable models (e.g. bivariate probit) are either undesirable or overly restrictive. Additionally, the bivariate probit model assumes a normal distribution for the latent treatment error, which may not be suitable in all contexts and can be less stable in practice than logistic specifications.
The model consists of a treatment equation and an outcome equation, linked through dependence in their unobserved components.
Treatment equation#
The binary treatment variable \(t_i \in \{0,1\}\) is modeled using a logistic latent-index formulation:
where \(Z_i\) is a vector of instrumental variables (and optional covariates), \(\beta_t\) is a vector of first-stage coefficients, and \(V_i\) is an unobserved disturbance. The latent error term follows a standard Logistic distribution,
This specification implies a logistic link for the treatment assignment mechanism, but the coefficients \(\beta_t\) should not be interpreted as marginal log-odds effects as in a standard logistic regression, since the latent disturbance \(V_i\) is explicitly represented rather than integrated out.
Outcome equation#
The continuous outcome \(y_i\) is modeled as
where \(X_i\) contains observed covariates (including the treatment), \(\beta_z\) are outcome coefficients, and the outcome error term satisfies
Under standard instrumental variables assumptions, the coefficient on the treatment in \(\beta_z\) has a causal interpretation and may be interpreted as a local average treatment effect (LATE).
Endogeneity and control function#
Endogeneity arises when the treatment error \(V_i\) is correlated with the outcome error \(U_i\). Rather than specifying a fully joint likelihood for \((V_i, U_i)\), the model adopts a control-function formulation that allows the conditional mean of \(U_i\) to depend on \(V_i\).
Specifically, the model assumes
where \(\rho \in (-1,1)\) is a dependence or sensitivity parameter and \(\sigma_V^2 = \pi^2 / 3\) is the variance of a standard Logistic random variable. Conditional on \(V_i\), the outcome error is approximated as
This variance-matching approximation treats the Logistic disturbance as if it were Normal with the same variance. As a result, \(\rho\) should not be interpreted as a Pearson correlation coefficient between latent errors. Instead, it serves as a sensitivity parameter that controls the strength and direction of unobserved confounding.
When \(\rho = 0\), the treatment is conditionally exogenous given covariates, and the model reduces to a standard outcome regression. As \(|\rho|\) increases, the contribution of the control function becomes stronger, reflecting greater endogeneity.
Prior specification#
Regression coefficients may be assigned standard Normal priors or variable-selection priors such as spike-and-slab formulations. When variable selection is enabled, coefficient-level mean and variance priors are ignored in favor of the selection prior.
The dependence parameter \(\rho\) is parameterized via a transformed unconstrained variable:
This prior concentrates mass near zero, regularizing weakly identified models and encouraging conservative estimates of endogeneity. Optional bounds may be imposed on \(\rho\) to support explicit sensitivity analysis.
Identification assumptions#
Identification relies on standard instrumental variables assumptions: instrument relevance, exclusion, and independence from unobserved outcome determinants. In addition, the model assumes that the logistic specification for treatment assignment and the linear specification for the outcome are adequate approximations to the underlying data-generating process.
Interpretation and scope#
This model provides a Bayesian instrumental variables estimator for binary treatments that emphasizes transparency and sensitivity analysis over full likelihood coherence. It is not equivalent to a bivariate probit or other fully joint latent-variable model, and the dependence parameter does not correspond to a true correlation between latent errors. Nevertheless, it offers a practical and interpretable framework for causal inference in applied settings where binary endogeneity is a central concern. The same variable selection priors discussed earlier can be applied to both treatment and outcome equations to help identify relevant predictors and instruments. Which we will do now.
formula = "Y_bin ~ T_bin + " + " + ".join(features)
instruments_formula = "T_bin ~ 1 + " + " + ".join(features)
# =========================================================================
# Model 1: Normal priors (no selection)
# =========================================================================
print("\n" + "-" * 80)
print("Model 1: Normal Priors Binary Treatment (No Variable Selection)")
print("-" * 80)
result_normal_binary = cp.InstrumentalVariable(
instruments_data=instruments_data,
data=data,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type=None, # No variable selection
binary_treatment=True,
priors={
"mus": [0, 0],
"sigmas": [1, 1],
"eta": 1,
"lkj_sd": 1,
},
)
result_horseshoe_binary = cp.InstrumentalVariable(
instruments_data=instruments_data,
data=data,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type="horseshoe",
vs_hyperparams={"c2_alpha": 3, "c2_beta": 3, "outcome": True},
binary_treatment=True,
)
Show code cell output
--------------------------------------------------------------------------------
Model 1: Normal Priors Binary Treatment (No Variable Selection)
--------------------------------------------------------------------------------
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 150/3000 [00:18<05:22, 8.83it/s]
Running chain 0: 10%|█ | 300/3000 [00:19<02:22, 19.01it/s]
Running chain 0: 15%|█▌ | 450/3000 [00:21<01:25, 29.78it/s]
Running chain 0: 20%|██ | 600/3000 [00:23<00:59, 40.14it/s]
Running chain 0: 25%|██▌ | 750/3000 [00:24<00:44, 50.37it/s]
Running chain 0: 30%|███ | 900/3000 [00:26<00:37, 55.28it/s]
Running chain 0: 35%|███▌ | 1050/3000 [00:29<00:33, 58.76it/s]
Running chain 0: 40%|████ | 1200/3000 [00:31<00:28, 62.29it/s]
Running chain 0: 45%|████▌ | 1350/3000 [00:33<00:25, 63.72it/s]
Running chain 0: 50%|█████ | 1500/3000 [00:35<00:22, 66.94it/s]
Running chain 0: 55%|█████▌ | 1650/3000 [00:37<00:19, 70.09it/s]
Running chain 0: 60%|██████ | 1800/3000 [00:39<00:16, 73.15it/s]
Running chain 0: 65%|██████▌ | 1950/3000 [00:41<00:14, 72.60it/s]
Running chain 0: 70%|███████ | 2100/3000 [00:43<00:12, 73.07it/s]
Running chain 0: 75%|███████▌ | 2250/3000 [00:45<00:09, 75.13it/s]
Running chain 0: 80%|████████ | 2400/3000 [00:47<00:07, 76.03it/s]
Running chain 0: 85%|████████▌ | 2550/3000 [00:48<00:05, 77.59it/s]
Running chain 0: 90%|█████████ | 2700/3000 [00:50<00:03, 77.47it/s]
Running chain 1: 100%|██████████| 3000/3000 [00:52<00:00, 57.38it/s]
Running chain 0: 95%|█████████▌| 2850/3000 [00:52<00:01, 77.78it/s]
Running chain 3: 100%|██████████| 3000/3000 [00:52<00:00, 56.69it/s]
Running chain 2: 100%|██████████| 3000/3000 [00:53<00:00, 56.13it/s]
Running chain 0: 100%|██████████| 3000/3000 [00:54<00:00, 55.01it/s]
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/pymc_models.py:900: UserWarning: Variable selection priors specified. The 'mus' and 'sigmas' in the priors dict will be ignored for beta coefficients in the treatment equation.Only 'eta' and 'lkj_sd' will be used from the priors dictwhere applicable.
self.build_model(
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 150/3000 [00:21<06:08, 7.74it/s]
Running chain 0: 10%|█ | 300/3000 [00:36<05:06, 8.80it/s]
Running chain 0: 15%|█▌ | 450/3000 [00:47<04:06, 10.36it/s]
Running chain 0: 20%|██ | 600/3000 [00:59<03:30, 11.39it/s]
Running chain 0: 25%|██▌ | 750/3000 [01:10<03:05, 12.12it/s]
Running chain 0: 30%|███ | 900/3000 [01:21<02:49, 12.36it/s]
Running chain 0: 35%|███▌ | 1050/3000 [01:32<02:31, 12.85it/s]
Running chain 0: 40%|████ | 1200/3000 [01:42<02:15, 13.29it/s]
Running chain 0: 45%|████▌ | 1350/3000 [01:53<02:02, 13.52it/s]
Running chain 0: 50%|█████ | 1500/3000 [02:03<01:48, 13.77it/s]
Running chain 0: 55%|█████▌ | 1650/3000 [02:14<01:38, 13.74it/s]
Running chain 0: 60%|██████ | 1800/3000 [02:25<01:26, 13.94it/s]
Running chain 0: 65%|██████▌ | 1950/3000 [02:37<01:17, 13.58it/s]
Running chain 0: 70%|███████ | 2100/3000 [02:51<01:12, 12.35it/s]
Running chain 0: 75%|███████▌ | 2250/3000 [03:06<01:04, 11.56it/s]
Running chain 0: 80%|████████ | 2400/3000 [03:21<00:54, 11.10it/s]
Running chain 2: 100%|██████████| 3000/3000 [03:32<00:00, 14.12it/s]
Running chain 0: 85%|████████▌ | 2550/3000 [03:36<00:41, 10.83it/s]
Running chain 0: 90%|█████████ | 2700/3000 [03:50<00:28, 10.67it/s]
Running chain 0: 95%|█████████▌| 2850/3000 [04:05<00:14, 10.56it/s]
Running chain 3: 100%|██████████| 3000/3000 [04:11<00:00, 11.91it/s]
Running chain 1: 100%|██████████| 3000/3000 [04:16<00:00, 11.72it/s]
Running chain 0: 100%|██████████| 3000/3000 [04:19<00:00, 11.56it/s]
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
fig, axs = plt.subplots(2, 2, figsize=(20, 12))
axs = axs.flatten()
az.plot_posterior(
result_horseshoe_binary.idata,
var_names=["beta_z"],
coords={"covariates": ["T_bin"]},
ax=axs[1],
label="Horseshoe",
color="green",
point_estimate="median",
)
az.plot_posterior(
result_normal_binary.idata,
var_names=["beta_z", "rho"],
coords={"covariates": ["T_bin"]},
ax=axs[0],
label="Normal",
point_estimate="median",
)
axs[0].axvline(3, color="black", linestyle="--")
axs[1].axvline(3, color="black", linestyle="--")
az.plot_posterior(
result_horseshoe_binary.idata,
var_names=["rho"],
ax=axs[3],
color="green",
label="Horseshoe",
)
az.plot_posterior(
result_normal_binary.idata,
var_names=["rho"],
ax=axs[2],
label="Normal",
)
axs[2].axvline(0.6, color="black", linestyle="--")
axs[3].axvline(0.6, color="black", linestyle="--");
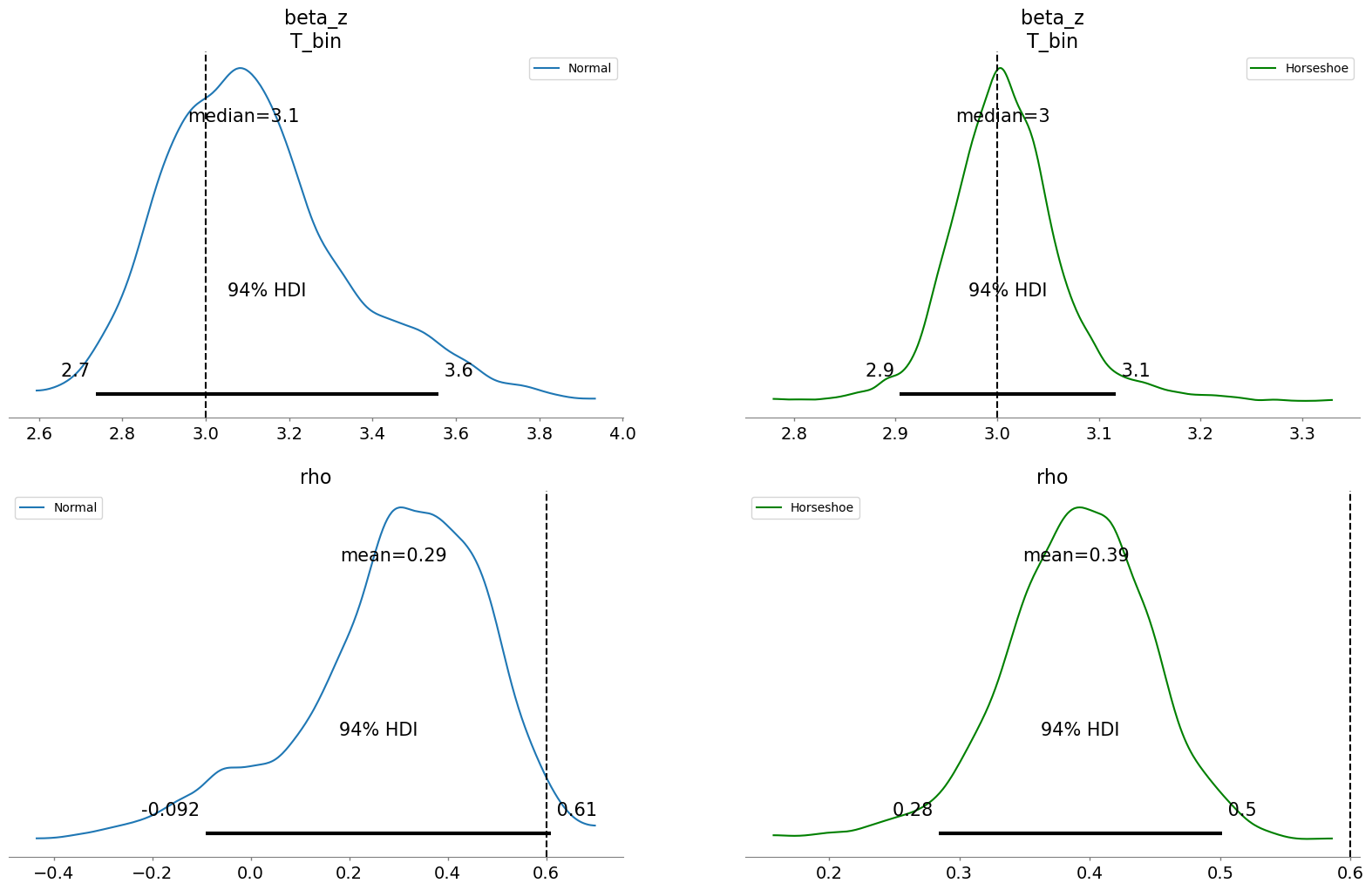
In the Binary case the biases due to weak instruments are overcome by both modelling strategies recovering the treatment effect well. But here as before, the uncertainty bounds on the treatment estimate are better approximated with the variable selection prior. Additionally, the rho parameter reflects correlation between the treatment and outcome errors on the logistic scale that is not fully resolved by either model. This doesn’t recover the true value that we set in the data generating process, but additionally we’re not modelling rho in the same way. The point is to use the control function to diagnose latent confounding and correct for it to recover the true treatment effect. The scale at which we model rho is somewhat immaterial so long as we can recover the true treatment effect. Both models do this well in this case.
An Applied Example: Weak but non-zero Instruments#
We now will explore the distinct challenges of using the Nevo cereal dataset—a cornerstone of industrial organization literature. While we’ve seen how “sparsity” or variable selection priors like the Horseshoe can work nicely with their ability to navigate high-dimensional spaces, they often encounter severe pathological bottlenecks when faced with weak instruments.
In the Nevo context, where instruments typically consist of prices in distant geographic markets (Hausman instruments), the signal-to-noise ratio is frequently too low to satisfy the aggressive “spike” of a shrinkage prior. This leads to a fragmented posterior where MCMC chains become trapped in local modes—either zeroing out crucial but weak signals or over-extending into the heavy tails—resulting in the high \(\hat{R}\) and low Effective Sample Size (ESS) observed in earlier runs. To illustrate these trade-offs, we will systematically compare the Regularized Horseshoe against a baseline Normal(0, 1) prior. We will demonstrate how the smooth, convex geometry of the Normal prior provides a more navigable energy landscape for the NUTS sampler, ensuring stable convergence at the cost of less selective regularization. By visualizing the rank plots and posterior densities of both approaches, we aim to show that for weakly identified structural models, the “best” prior is often the one that prioritizes sampling stability and global identification over aggressive variable selection. As usual, the answer is to the question of which prior to use, is driven by what influence you expect your variables to have in the model.
import causalpy as cp
df_nevo = pd.read_csv("../../../causalpy/data/data_nevo.csv", decimal=",")
df_nevo["log_share"] = np.log(df_nevo["share"])
df_nevo.info()
Show code cell output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2256 entries, 0 to 2255
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 2256 non-null int64
1 firmbr 2256 non-null int64
2 firm 2256 non-null int64
3 brand 2256 non-null int64
4 city 2256 non-null int64
5 year 2256 non-null int64
6 quarter 2256 non-null int64
7 share 2256 non-null float64
8 price 2256 non-null float64
9 sugar 2256 non-null float64
10 mushy 2256 non-null float64
11 z1 2256 non-null float64
12 z2 2256 non-null float64
13 z3 2256 non-null float64
14 z4 2256 non-null float64
15 z5 2256 non-null float64
16 z6 2256 non-null float64
17 z7 2256 non-null float64
18 z8 2256 non-null float64
19 z9 2256 non-null float64
20 z10 2256 non-null float64
21 z11 2256 non-null float64
22 z12 2256 non-null float64
23 z13 2256 non-null float64
24 z14 2256 non-null float64
25 z15 2256 non-null float64
26 z16 2256 non-null float64
27 z17 2256 non-null float64
28 z18 2256 non-null float64
29 z19 2256 non-null float64
30 z20 2256 non-null float64
31 log_share 2256 non-null float64
dtypes: float64(25), int64(7)
memory usage: 564.1 KB
ols_formula = "log_share ~ price + sugar + mushy"
ols_res = ols(ols_formula, data=df_nevo).fit()
ols_res.summary()
| Dep. Variable: | log_share | R-squared: | 0.081 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.080 |
| Method: | Least Squares | F-statistic: | 66.33 |
| Date: | Thu, 25 Dec 2025 | Prob (F-statistic): | 4.26e-41 |
| Time: | 16:26:31 | Log-Likelihood: | -3424.2 |
| No. Observations: | 2256 | AIC: | 6856. |
| Df Residuals: | 2252 | BIC: | 6879. |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -3.7173 | 0.107 | -34.870 | 0.000 | -3.926 | -3.508 |
| price | -9.6336 | 0.840 | -11.473 | 0.000 | -11.280 | -7.987 |
| sugar | 0.0454 | 0.004 | 10.825 | 0.000 | 0.037 | 0.054 |
| mushy | 0.0550 | 0.050 | 1.109 | 0.268 | -0.042 | 0.152 |
| Omnibus: | 13.848 | Durbin-Watson: | 2.064 |
|---|---|---|---|
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 14.044 |
| Skew: | -0.193 | Prob(JB): | 0.000892 |
| Kurtosis: | 2.969 | Cond. No. | 379. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
instruments = [col for col in df_nevo.columns if "z" in col]
instruments_formula = "price ~ 1 + sugar + mushy + " + " + ".join(instruments)
instruments_formula
formula = "log_share ~ price + sugar + mushy"
sample_kwargs = {
"draws": 1000,
"tune": 1000,
"chains": 4,
"cores": 4,
"target_accept": 0.9,
"progressbar": True,
"random_seed": 42,
"nuts_sampler": "numpyro",
}
result_horseshoe_nevo = cp.InstrumentalVariable(
instruments_data=df_nevo,
data=df_nevo,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type="horseshoe",
vs_hyperparams={"outcome": False, "c2_alpha": 2, "c2_beta": 8, "nu": 5},
binary_treatment=False,
)
Show code cell output
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/experiments/instrumental_variable.py:137: UserWarning: Warning. The treatment variable is not Binary.
We will use the multivariate normal likelihood
for continuous treatment.
self.input_validation()
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/pymc_models.py:900: UserWarning: Variable selection priors specified. The 'mus' and 'sigmas' in the priors dict will be ignored for beta coefficients in the treatment equation.Only 'eta' and 'lkj_sd' will be used from the priors dictwhere applicable.
self.build_model(
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 100/2000 [00:04<01:07, 27.95it/s]
Running chain 0: 10%|█ | 200/2000 [00:10<01:25, 21.08it/s]
Running chain 0: 15%|█▌ | 300/2000 [00:16<01:28, 19.31it/s]
Running chain 0: 20%|██ | 400/2000 [00:22<01:26, 18.46it/s]
Running chain 0: 25%|██▌ | 500/2000 [00:27<01:24, 17.81it/s]
Running chain 0: 30%|███ | 600/2000 [00:33<01:19, 17.53it/s]
Running chain 0: 35%|███▌ | 700/2000 [00:39<01:14, 17.37it/s]
Running chain 0: 40%|████ | 800/2000 [00:45<01:09, 17.18it/s]
Running chain 0: 45%|████▌ | 900/2000 [00:51<01:04, 17.13it/s]
Running chain 0: 50%|█████ | 1000/2000 [00:57<00:58, 17.09it/s]
Running chain 0: 55%|█████▌ | 1100/2000 [01:03<00:52, 17.14it/s]
Running chain 0: 60%|██████ | 1200/2000 [01:09<00:46, 17.18it/s]
Running chain 0: 65%|██████▌ | 1300/2000 [01:15<00:41, 16.96it/s]
Running chain 0: 70%|███████ | 1400/2000 [01:21<00:35, 16.88it/s]
Running chain 0: 75%|███████▌ | 1500/2000 [01:26<00:29, 16.95it/s]
Running chain 0: 80%|████████ | 1600/2000 [01:32<00:23, 17.01it/s]
Running chain 0: 85%|████████▌ | 1700/2000 [01:38<00:17, 16.97it/s]
Running chain 0: 90%|█████████ | 1800/2000 [01:44<00:11, 16.88it/s]
Running chain 0: 95%|█████████▌| 1900/2000 [01:50<00:05, 16.96it/s]
Running chain 0: 100%|██████████| 2000/2000 [01:56<00:00, 17.20it/s]
Running chain 3: 100%|██████████| 2000/2000 [01:56<00:00, 17.14it/s]
Running chain 1: 100%|██████████| 2000/2000 [01:56<00:00, 17.13it/s]
Running chain 2: 100%|██████████| 2000/2000 [01:56<00:00, 17.09it/s]
There were 11 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
sample_kwargs = {
"draws": 1000,
"tune": 1000,
"chains": 4,
"cores": 4,
"target_accept": 0.9,
"progressbar": True,
"random_seed": 42,
"nuts_sampler": "numpyro",
}
result_nevo = cp.InstrumentalVariable(
instruments_data=df_nevo,
data=df_nevo,
instruments_formula=instruments_formula,
formula=formula,
model=cp.pymc_models.InstrumentalVariableRegression(sample_kwargs=sample_kwargs),
vs_prior_type=None,
vs_hyperparams=None,
binary_treatment=False,
priors={
"mus": [0, 0],
"sigmas": [1, 5],
"eta": 1,
"lkj_sd": 1,
},
)
Show code cell output
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/causalpy/experiments/instrumental_variable.py:137: UserWarning: Warning. The treatment variable is not Binary.
We will use the multivariate normal likelihood
for continuous treatment.
self.input_validation()
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 5%|▌ | 100/2000 [00:03<00:36, 51.76it/s]
Running chain 0: 10%|█ | 200/2000 [00:07<01:05, 27.50it/s]
Running chain 0: 15%|█▌ | 300/2000 [00:13<01:16, 22.18it/s]
Running chain 0: 20%|██ | 400/2000 [00:18<01:17, 20.57it/s]
Running chain 0: 25%|██▌ | 500/2000 [00:24<01:18, 19.22it/s]
Running chain 0: 30%|███ | 600/2000 [00:30<01:14, 18.90it/s]
Running chain 0: 35%|███▌ | 700/2000 [00:35<01:09, 18.76it/s]
Running chain 0: 40%|████ | 800/2000 [00:41<01:05, 18.45it/s]
Running chain 0: 45%|████▌ | 900/2000 [00:46<01:00, 18.25it/s]
Running chain 0: 50%|█████ | 1000/2000 [00:52<00:54, 18.41it/s]
Running chain 0: 55%|█████▌ | 1100/2000 [00:57<00:49, 18.34it/s]
Running chain 0: 60%|██████ | 1200/2000 [01:03<00:43, 18.33it/s]
Running chain 0: 65%|██████▌ | 1300/2000 [01:08<00:38, 18.32it/s]
Running chain 0: 70%|███████ | 1400/2000 [01:14<00:33, 18.15it/s]
Running chain 0: 75%|███████▌ | 1500/2000 [01:19<00:27, 18.12it/s]
Running chain 0: 80%|████████ | 1600/2000 [01:25<00:21, 18.20it/s]
Running chain 0: 85%|████████▌ | 1700/2000 [01:30<00:16, 18.18it/s]
Running chain 0: 90%|█████████ | 1800/2000 [01:36<00:11, 17.86it/s]
Running chain 0: 95%|█████████▌| 1900/2000 [01:41<00:05, 18.03it/s]
Running chain 1: 100%|██████████| 2000/2000 [01:45<00:00, 18.89it/s]
Running chain 0: 100%|██████████| 2000/2000 [01:47<00:00, 18.62it/s]
Running chain 2: 100%|██████████| 2000/2000 [01:48<00:00, 18.39it/s]
Running chain 3: 100%|██████████| 2000/2000 [01:56<00:00, 17.23it/s]
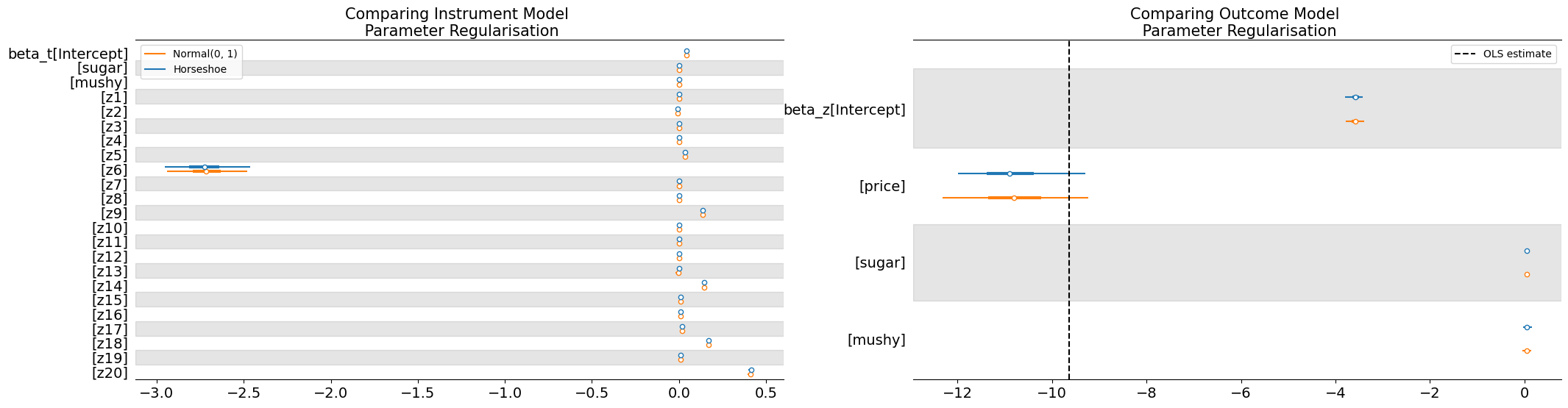
The parameter estimates suggest a robust finding where the instrumental variable design has accounted for some of the bias in the OLS estimate and corrected for unobserved endogeniety.
fig, axs = plt.subplots(1, 2, figsize=(25, 6))
axs = axs.flatten()
az.plot_forest(
[result_horseshoe_nevo.idata, result_nevo.idata],
var_names=["beta_t"],
combined=True,
model_names=["Horseshoe", "Normal(0, 1)"],
ax=axs[0],
)
az.plot_forest(
[result_horseshoe_nevo.idata, result_nevo.idata],
var_names=["beta_z"],
combined=True,
model_names=["Horseshoe", "Normal(0, 1)"],
ax=axs[1],
)
axs[1].set_title("Comparing Outcome Model \n Parameter Regularisation", fontsize=15)
axs[0].set_title("Comparing Instrument Model \n Parameter Regularisation", fontsize=15)
axs[1].axvline(ols_res.params["price"], linestyle="--", label="OLS estimate", color="k")
axs[1].legend()
<matplotlib.legend.Legend at 0x362c0cf50>
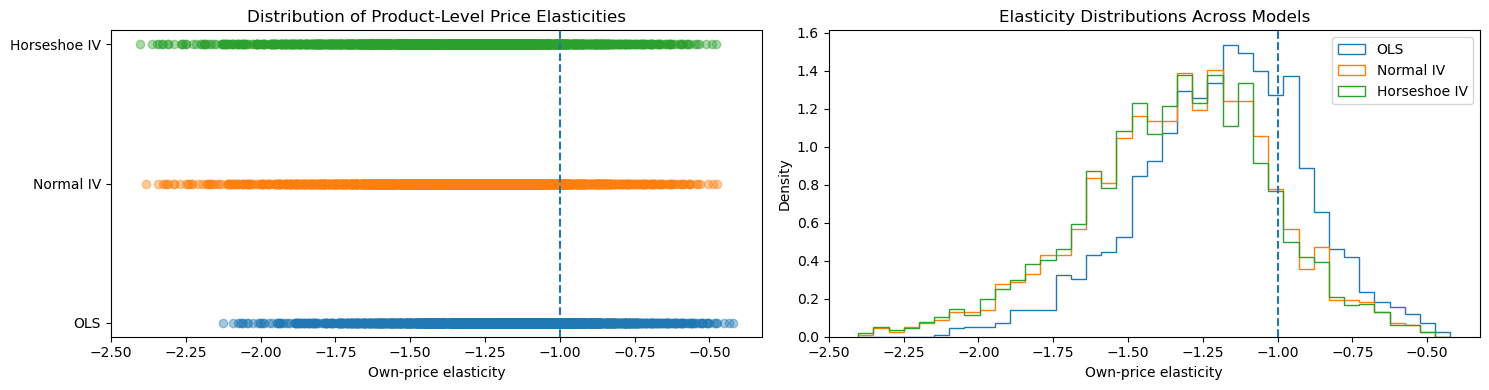
The own-price elasticity of demand measures the percentage change in a product’s market share resulting from a one-percent change in its price and is a primary indicator of market competitiveness and substitution patterns. Products with elastic demand (elasticity less than −1) face strong competitive pressure, while inelastic demand suggests limited substitution and potentially implausible market power in differentiated-product settings such as ready-to-eat cereals.
Viewing the Nevo results through the distribution of product-level elasticities is therefore crucial, because economic plausibility is defined at the product level rather than by a single price coefficient. Small differences in the estimated price effect can translate into qualitatively different elasticity implications across products due to heterogeneity in prices and market shares. Comparing elasticity distributions across OLS and IV specifications highlights how correcting for price endogeneity shifts mass away from implausibly inelastic demand, while the choice of prior further shapes dispersion and tail behavior. This elasticity-based perspective provides a transparent and policy-relevant diagnostic of how modeling choices propagate into substantive conclusions about competition and demand in the Nevo dataset.
alpha_horseshoe = az.summary(result_horseshoe_nevo.idata, var_names=["beta_z"])[
"mean"
].loc["beta_z[price]"]
alpha_normal = az.summary(result_nevo.idata, var_names=["beta_z"])["mean"].loc[
"beta_z[price]"
]
alpha_ols = ols_res.params["price"]
elas_ols = alpha_ols * df_nevo["price"] * (1 - df_nevo["share"])
elas_normal = alpha_normal * df_nevo["price"] * (1 - df_nevo["share"])
elas_horseshoe = alpha_horseshoe * df_nevo["price"] * (1 - df_nevo["share"])
print("Inelastic (OLS):", (elas_ols >= -1).sum())
print("Inelastic (Normal IV):", (elas_normal >= -1).sum())
print("Inelastic (Horseshoe IV):", (elas_horseshoe >= -1).sum())
Inelastic (OLS): 586
Inelastic (Normal IV): 292
Inelastic (Horseshoe IV): 276
Show code cell source
elas = {
"OLS": elas_ols.values,
"Normal IV": elas_normal.values,
"Horseshoe IV": elas_horseshoe.values,
}
fig, axs = plt.subplots(1, 2, figsize=(15, 4))
axs = axs.flatten()
ax = axs[0]
ax1 = axs[1]
y_positions = np.arange(len(elas))
for i, (label, values) in enumerate(elas.items()):
y = np.full_like(values, i, dtype=float)
ax.scatter(values, y, alpha=0.4)
ax.set_yticks(y_positions)
ax.set_yticklabels(list(elas.keys()))
ax.axvline(-1, linestyle="--") # unit elasticity reference
ax.set_xlabel("Own-price elasticity")
ax.set_title("Distribution of Product-Level Price Elasticities")
bins = np.linspace(
min(v.min() for v in elas.values()), max(v.max() for v in elas.values()), 40
)
for label, values in elas.items():
ax1.hist(values, bins=bins, density=True, histtype="step", label=label)
ax1.axvline(-1, linestyle="--")
ax1.set_xlabel("Own-price elasticity")
ax1.set_ylabel("Density")
ax1.legend()
ax1.set_title("Elasticity Distributions Across Models")
plt.tight_layout()
plt.show()
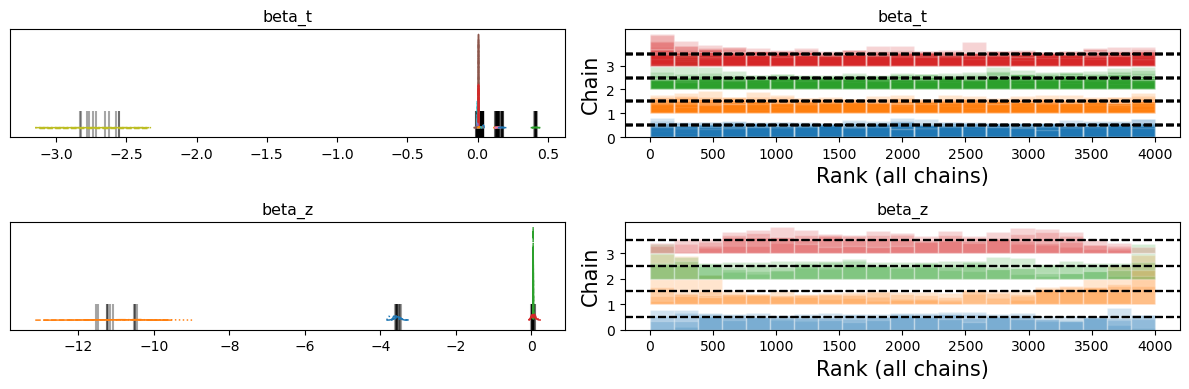
Comparing Sampling Regimes#
Despite roughly comparable IV results, we can now examine the trace plots to see how the horseshoe prior seems to struggle with sampling some of the values. The black bars on the left indicating divergences and the rank-bar plots on the right suggesting inconsistency across the sampling chains as they exceed the boundary of the uniform distribution on chains.
az.plot_trace(
result_horseshoe_nevo.idata, var_names=["beta_t", "beta_z"], kind="rank_bars"
)
plt.tight_layout()
Conversely, the normal(0, 1) regularisation works much better and samples effectively and consistently across the chains.
az.plot_trace(result_nevo.idata, var_names=["beta_t", "beta_z"], kind="rank_bars")
plt.tight_layout()
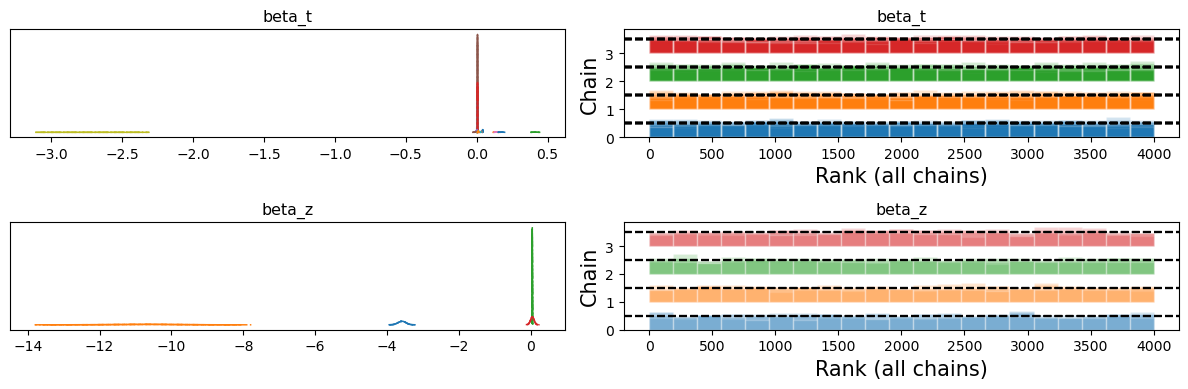
This demonstration shows that the Horseshoe regularisation can identify signal in the data, but where we have weak instruments, it gets caught deciding how strongly to zero-out the near zero coefficients. When chains disagree on how decisively to zero out these predictors the sampling can get stuck.
Conclusion: Choosing Your Path Through Uncertainty#
Variable selection priors offer a principled way to navigate the tension between model complexity and causal identification. Rather than forcing binary decisions about which variables to include, these priors encode our uncertainty about variable relevance directly into the inferential framework. But as we’ve seen, the choice between spike-and-slab and horseshoe reflects deeper commitments about how sparsity manifests in the world.
The spike-and-slab prior embodies decisiveness. It asks: which variables truly matter? By pushing coefficients toward exactly zero or allowing them to take on substantial values, it produces interpretable inclusion probabilities that clearly communicate which predictors the model has “selected.” This approach shines when you believe that many potential confounders are genuine noise—included out of caution but ultimately irrelevant to the causal mechanism. The discrete nature of selection also makes results easier to communicate to stakeholders who think in terms of “what factors matter?”
The horseshoe prior embraces nuance. It acknowledges that effects exist on a continuum, and that small but real contributions shouldn’t be entirely zeroed out. The continuous shrinkage allows weak signals to persist (heavily damped) while strong signals emerge largely unscathed. This is valuable when you suspect that multiple confounders have genuine but varying degrees of influence, and when premature exclusion of any single variable might introduce bias. The regularization parameter \(c^2\) acts as a safeguard, preventing even the horseshoe’s aggressive shrinkage from overwhelming genuinely large effects.
In our simulations, both approaches identified the true treatment effect of 3, though they arrived there differently. The spike-and-slab showed more confidence, producing tighter posterior intervals by decisively excluding noise variables. The horseshoe’s bi-modal posterior in some specifications revealed its uncertainty about the appropriate level of sparsity a kind of probabilistic humility that spike-and-slab’s discrete choices don’t allow.
Practical Guidance#
Use spike-and-slab when you have strong priors about sparsity (many potential confounders, few true ones), when interpretability matters (stakeholders want to know “what’s included?”), or when you’re willing to trade some flexibility for more decisive inference.
Use horseshoe when you’re uncertain about sparsity levels, when small effects might still matter for causal identification, or when you want the model to smoothly adapt its shrinkage to the data without hard inclusion/exclusion decisions.
Use neither when theory clearly identifies your confounders, when sample size is large relative to the number of predictors, or when the cost of Type I errors (including irrelevant variables) is low relative to Type II errors (excluding true confounders)
Final Thoughts#
Variable selection priors don’t eliminate the need for causal reasoning. They don’t tell you which variables are causally relevant, only which are statistically predictive. But when used thoughtfully—guided by theory about potential confounders, informed by domain knowledge about likely sparsity patterns, and validated through sensitivity analysis. They offer a middle path between the Scylla of over-specification (including everything) and the Charybdis of under-specification (excluding too much). Used within a joint model of treatment and outcome variable, the argument of a variable selection routine represents an attempt to calibrate the parameters to select the instrument structure. What variable selection is really doing in joint treatment-outcome models is calibrating the parameters to discover patterns consistent with instrument structure if such structure exists in the data. The horseshoe shrinks away coefficients that appear redundant given the covariance structure between treatment, outcome, and covariates. The spike-and-slab actively excludes variables that don’t contribute to explaining either margin after accounting for shared variation.
The ideal use of variable selection in instrumental variable designs is not as a replacement for domain knowledge but as a consistency check. The real power of these methods lies not in automation but in transparency. By making variable selection part of the posterior distribution rather than a pre-processing step, we can quantify and communicate our uncertainty about model structure itself. This moves us closer to the goal of all principled causal inference: not just estimating effects, but understanding the limits of what we can learn from the data we have.
As always in causal inference, the model is a question posed to the data. Variable selection priors help us ask that question more precisely, but we still need theory to tell us if we’re asking the right question at all.